Understanding how LLMs work.
When I first started learning about LLMs, it helped me to think of them in a very simple way: at their core is just a model trained on a massive amount of human-generated text, which ultimately tries to predict the next word (token). The scale of the training is huge, we are talking about billions of different sentences from websites, blogs, news, forums, etc. At their core, language models generate text by predicting the most probable next token, a paradigm popularized in large-scale models such as Language Models are Few-Shot Learners paper.
How simple it is, and how powerful. It can present that knowledge in a coherent and understandable way. This ability is possible thanks to a neural network architecture based on an attention mechanism known as transformers, introduced in the paper Attention Is All You Need paper.
Limitations of LLMs
That said, while LLMs are impressive, they definitely have limitations that are important to keep in mind.
First of all, the knowledge cut-off. Model training is an expensive and time-consuming process. It takes large volumes of data and months to train an LLM. Events happening after the training is finished are simply not part of its knowledge.
Second, there’s the problem of hallucinations. This issue has been studied extensively, for example in benchmarks like TruthfulQA, which show that models can produce convincing but incorrect answers, even when they appear confident. This happens because the model generates statistically plausible responses rather than verifying facts against a reliable source.
Finally, there’s a limitation around private or proprietary knowledge. LLMs don’t have access to internal company data, confidential documents, or anything that isn’t publicly available in their training data.
So naturally, this raises a question: if LLMs have these limitations, can they really be adopted widely in real-world applications?
Introducing Retrieval-Augmented Generation (RAG)
This is where Retrieval-Augmented Generation (RAG), introduced in Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks paper (https://arxiv.org/abs/2005.11401), comes into the picture. As the creator of LlamaIndex, Jerry Liu, says:
“RAG is just a hack” , but a very powerful one.
Building Intuition: How RAG Works
What would you do to help an LLM answer a specific question? Logically, we would provide the information directly in the prompt, or maybe even link to a source like Wikipedia, right?
What we can do is copy and paste a piece of information (context) together with our query directly into the LLM. And here it is, it is able to comprehend the additional information we provided, distill it, and respond with more precise and accurate information. This is an oversimplified example of what RAG is doing.
What is RAG and Why It Matters
The main idea of RAG is to provide additional information, which can be achieved in different ways. A new LLM can be trained from scratch to include new data, or an existing model can be fine-tuned. However, both approaches require a significant amount of data and computational resources. Training models can therefore be costly and not always yield the best results. RAG, on the other hand, is often more cost-effective, flexible, and does not require powerful compute resources or long training times.
As the name implies, retrieval-augmented generation can be explained in three steps:
- It retrieves relevant information from a data source external to the LLM (Wikipedia, for example)
- It augments the input to the LLM with that external information
- Finally, the LLM generates a more accurate result
What Does a RAG System Look Like?
The Generation Pipeline
The main flow of RAG can be represented in five steps:
- The user asks a question
- The system searches for information relevant to the user input
- The relevant information is retrieved and added to the input question
- This enriched input is passed to an LLM
- The LLM responds with a contextual answer
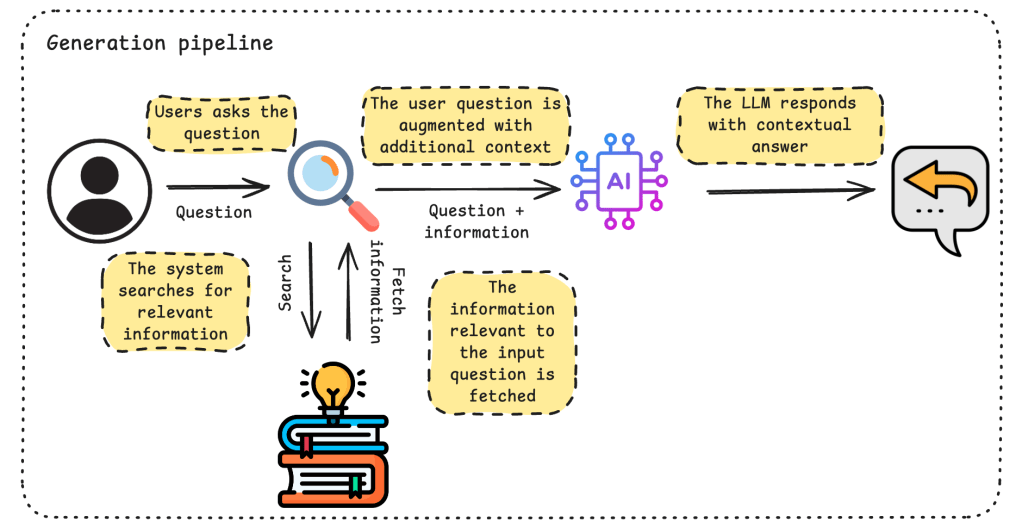
A generation pipeline is the step-by-step process that takes a user’s input, optionally adds relevant context, and passes it through an LLM to produce a final answer. This is the generation pipeline in its simplest form.
Indexing pipeline
Before the generation pipeline can work effectively, the system must first prepare and organize the external data sources. This involves answering key questions:
Data source considerations
- Where is the data located?
- Is it publicly available (e.g., Wikipedia) or internal (e.g., company handbooks)?
- Does it come from third-party databases?
- Are we using a single source or multiple sources?
Data characteristics
- What formats are used (PDF, Word, JSON, plain text)?
- Is the data accessed via APIs?
- Is the information spread across multiple documents?
To address these requirements, we need to implement another series of steps:
- Connect to the identified external sources
- Extract documents and parse text from them
- Break down long pieces of information into smaller, manageable chunks
- Convert these chunks into a suitable format (e.g., embeddings)
- Store this information
This process is commonly referred to as the indexing pipeline. Its goal is to transform raw, unstructured data into a format that can be efficiently searched and retrieved at query time. The quality of this step is critical, decisions made here, such as how documents are chunked or embedded, directly impact how well relevant information can be retrieved later.
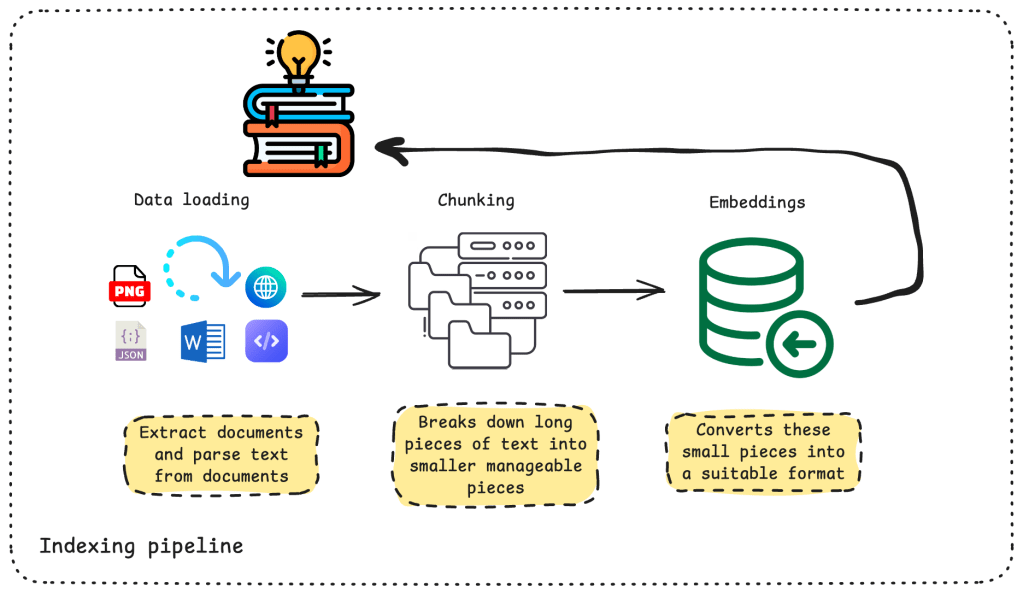
The diagram above illustrates how raw data flows through the indexing pipeline and is transformed into a structured representation (typically a vector index) that the retrieval system can use.
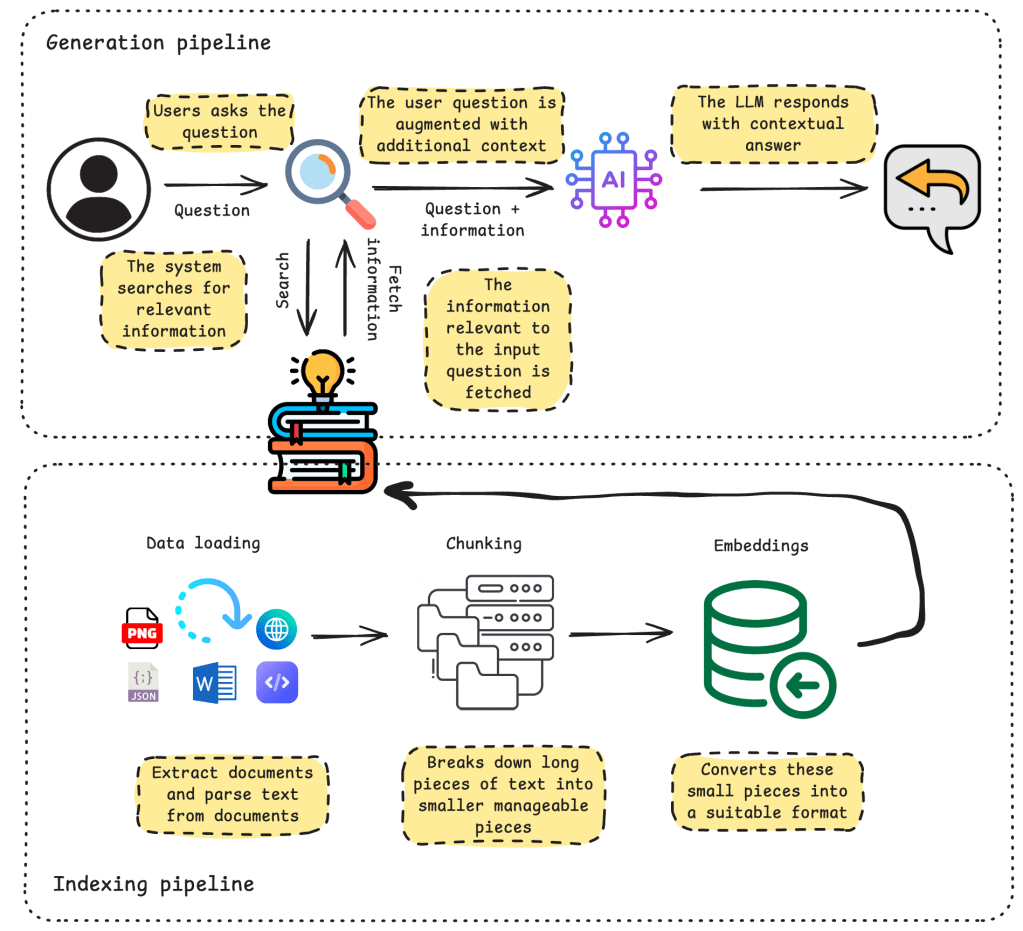
How Indexing and Generation Work Together
In practice, the indexing and generation pipelines are tightly connected: the way data is prepared during indexing directly influences the quality of the retrieved context and, ultimately, the final answer generated by the LLM.
Evaluating a RAG System
When thinking about evaluating a RAG system, we need to look at what’s happening at every step along the way: the prompt, the retrieved context, and the generated response.
Did we retrieve the right information?
Is the context actually relevant to the user’s question? Because if the retriever brings back weak or unrelated information, even the best LLM won’t be able to produce a good answer. The output is only as good as the input it receives.
Did the LLM actually pay attention to the retrieved context?
Even though RAG is designed to reduce hallucinations, the model can still ignore or underuse the provided information. This can happen for several reasons, such as poor prompt design, noisy or overly long context, or limitations in how attention is distributed.
Does the answer actually address the original question?
At the end of the day, this is what matters most. Even if retrieval and generation seem correct in isolation, the final response needs to be clearly relevant and useful to the user’s intent.
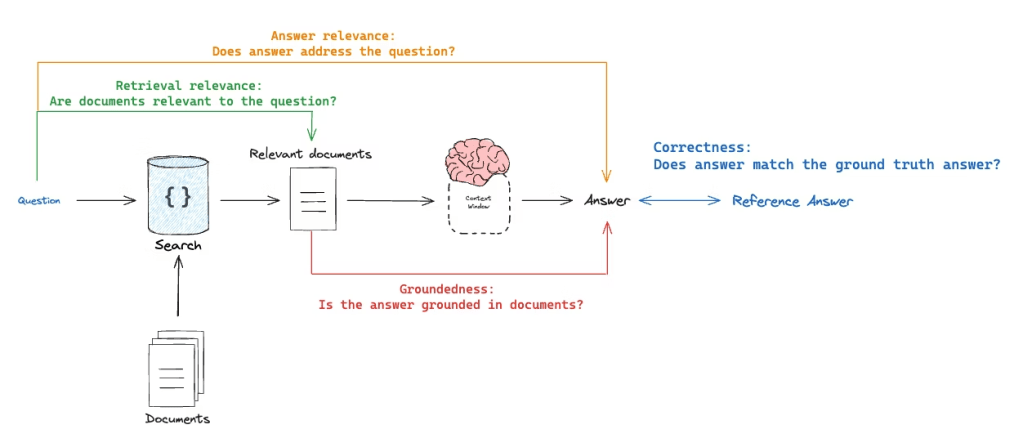
Source: https://docs.langchain.com/langsmith/evaluate-rag-tutorial
What’s Next
In the next article, I will introduce our RAG application and walk through a practical example of how to evaluate it using one of the popular frameworks.
